Lily (Xianling) Zhang is a Machine Learning Research Scientist at Ford Autonomy, Palo Alto, CA, located at Ford Greenfield Labs, Stanford Research Park. She is working on Perception and Prediction for autonomous driving tasks.
My research interests include
3D perception and motion prediction
Geometric scene understanding based data manipulation(scene relighting) to significantly improve the performance of SOTA CenterTrack algorithm.
Dataset bias identification using perceptual similarity based data clustering for large scale dataset meta labeling, similar data searching, balanced data selection for training set curation.
Data augmentation via GANs that achieves consistent improvement over multple AV task: parking slot detection, highway lane segmentation, and monodepth estimation.
At NVIDIA GTC 2023, I am going to give a talk using AI based data algorithms to achieve autonomous driving dataset diversity. We will have live discussion on Tuesday, Mar 21. 2:00 PM - 2:50 PM PDT. Link to the talk (S51407)
Neural fields have recently enjoyed great success in representing and rendering 3D scenes. However, most state-of-the-art implicit representations model static or dynamic scenes as a whole, with minor variations. Existing work on learning disentangled world and object neural fields do not consider the problem of composing objects into different world neural fields in a lighting-aware manner. We present Lighting-Aware Neural Field (LANe) for the compositional synthesis of driving scenes in a physically consistent manner. Specifically, we learn a scene representation that disentangles the static background and transient elements into a world-NeRF and class-specific object-NeRFs to allow compositional synthesis of multiple objects in the scene. Furthermore, we explicitly designed both the world and object models to handle lighting variation, which allows us to compose objects into scenes with spatially varying lighting. This is achieved by constructing a light field of the scene and using it in conjunction with a learned shader to modulate the appearance of the object NeRFs. We demonstrate the performance of our model on a synthetic dataset of diverse lighting conditions rendered with the CARLA simulator, as well as a novel real-world dataset of cars collected at different times of the day. Our approach shows that it outperforms state-of-the-art compositional scene synthesis on the challenging dataset setup, via composing object-NeRFs learned from one scene into an entirely different scene whilst still respecting the lighting variations in the novel scene. For more results, please visit our project website https://lane-composition.github.io/.
SIMBAR: Single Image-Based Scene Relighting for Effective Data Augmentation for Automated Driving Vision Tasks
Xianling Zhang, Nathan Tseng, Ameerah Syed, and
2 more authors
Real-world autonomous driving datasets comprise of images aggregated from different drives on the road. The ability to relight captured scenes to unseen lighting conditions, in a controllable manner, presents an opportunity to augment datasets with a richer variety of lighting conditions, similar to what would be encountered in the real-world. This paper presents a novel image-based relighting pipeline, SIMBAR, that can work with a single image as input. To the best of our knowledge, there is no prior work on scene relighting leveraging explicit geometric representations from a single image. We present qualitative comparisons with prior multi-view scene relighting baselines. To further validate and effectively quantify the benefit of leveraging SIMBAR for data augmentation for automated driving vision tasks, object detection and tracking experiments are conducted with a state-of-the-art method, a Multiple Object Tracking Accuracy (MOTA) of 93.3% is achieved with CenterTrack on SIMBAR-augmented KITTI-an impressive 9.0% relative improvement over the baseline MOTA of 85.6% with CenterTrack on original KITTI, both models trained from scratch and tested on Virtual KITTI. For more details and SIMBAR relit datasets, please visit our project website (https://simbarv1.github.io/).
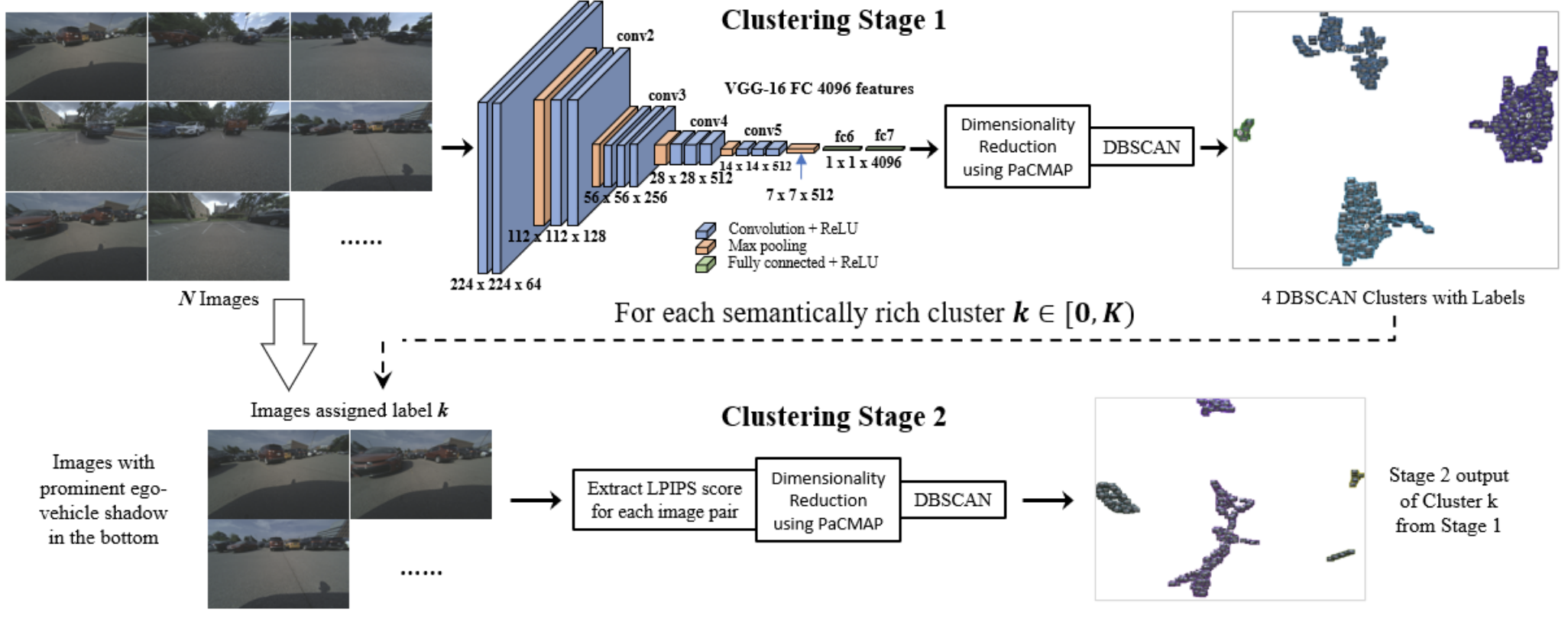
deepPIC: Deep Perceptual Image Clustering for Identifying Bias in Vision Datasets
Nikita Jaipuria, Katherine Stevo, Xianling Zhang, and
4 more authors
Dataset bias in manually collected datasets is a known problem in computer vision. In safety-critical applications such as autonomous driving, these biases can lead to catastrophic errors from models trained on such datasets, jeopardizing the safety of users and their surroundings. Being able to unpuzzle the bias in a given dataset, and across datasets, is an essential tool for building safe and responsible AI. In this paper, we present deepPIC: deep Perceptual Image Clustering, a novel hierarchical clustering pipeline that leverages deep perceptual features to visualize and understand bias in unstructured and unlabeled datasets. It does so by effectively highlighting nuanced subcategories of information embedded within the data (such as multiple but repetitive shadow types) that typically are hard and/or expensive to annotate. Through experiments on a variety of image datasets, both open-source and internal, we demonstrate the effectiveness of deepPIC in (i) singling out errors in metadata from open-source datasets such as BDD100K;(ii) automatic nuanced metadata annotation;(iii) mining for edge cases;(iv) visualizing inherent bias both within and across multiple datasets; and (v) capturing synthetic data limitations; thus highlighting the wide variety of applications this pipeline can be applied to. All clustering results included here have been uploaded with image thumbnails on our project website-https://alchemz. github. io/unpuzzle_dataset_bias/. We recommend zooming in for best impact.
Deflating Dataset Bias Using Synthetic Data Augmentation
Nikita Jaipuria, Xianling Zhang, Rohan Bhasin, and
5 more authors
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Jun 2020
Deep Learning has seen an unprecedented increase in vision applications since the publication of large-scale object recognition datasets and introduction of scalable compute hardware. State-of-the-art methods for most vision tasks for Autonomous Vehicles (AVs) rely on supervised learning and often fail to generalize to domain shifts and/or outliers. Dataset diversity is thus key to successful real-world deployment. No matter how big the size of the dataset, capturing long tails of the distribution pertaining to task-specific environmental factors is impractical. The goal of this paper is to investigate the use of targeted synthetic data augmentation - combining the benefits of gaming engine simulations and sim2real style transfer techniques - for filling gaps in real datasets for vision tasks. Empirical studies on three different computer vision tasks of practical use to AVs - parking slot detection, lane detection and monocular depth estimation - consistently show that having synthetic data in the training mix provides a significant boost in cross-dataset generalization performance as compared to training on real data only, for the same size of the training set.